

Last Week, This Week #5 – Christmas Day, 2024
OpenAI surprises with o3 model, and more saber-rattling from Congress.


Delivered to your inbox every Monday morning, LWTW is a rundown of the previous week’s happenings in AI governance in America. News, articles, opinion pieces, and more, to bring you up to speed for the week ahead.
This week we witnessed a shift en masse in many peoples’ timelines, with the announcement of OpenAI’s o3 model. Coming on the final day of their ‘12 Days of OpenAI’ series of feature releases, the most recent model in the company’s o-series smashed through some tests and surpassed some benchmarks that many thought would continue to elude LLMs for a significant time – years, even.
For one, the model achieved a score of 88% on the ARC-AGI test. Developed by Francois Chollet in 2019 the Abstraction and Reasoning Corpus (ARC) is a series of abstract reasoning tests that are designed to specifically test for reasoning capabilities, thereby separating the stochastic-parrot-cum-next-token-predictor from the “truly” intelligent.
Two months ago, Chollet had predicted that it would take 1 to 3 years before we saw significant progress on ARC. Instead, progress over the past six months has essentially been a vertical line. o3 also set records for EpochAI’s FrontierMath, SWE-Bench Verified, and multiple other STEM benchmarks.
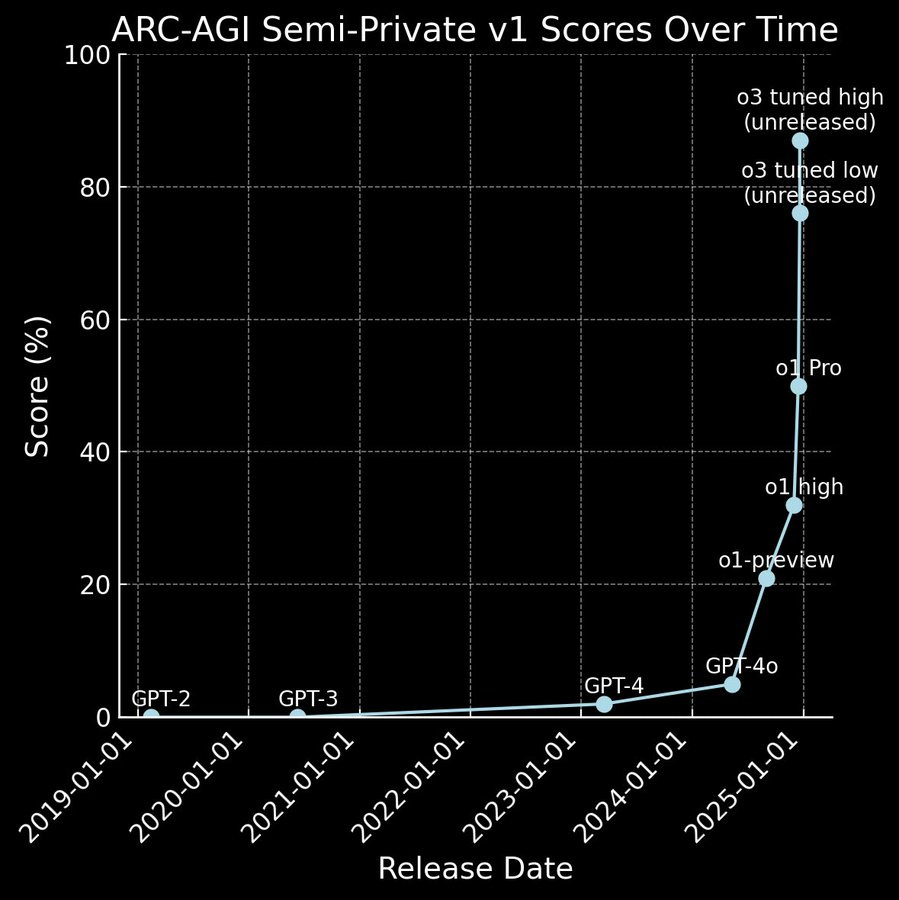
While the model still faces hurdles to its practical implications becoming fully realized–a high score of 88% was achieved at a cost of over $3400 per task, and is estimated to have cost over $1M to run the benchmark as a whole–its results were met with surprise from the community, and have shaken many people’s expectations about when we may see truly transformative AI.
Accordingly, we begin with…
…some thoughts from OpenAI’s Yoanadav Shavit about what o3 means for AI policy.
He argues that 1) the compute required for powerful AI will be little enough to allow “everyone [to] probably have [artificial superintelligence]”, that 2) the corporate tax rate will be the most important tax, whereby governments raise revenue by taxing AI agents via the corporations they’re registered to, and 3) that “the thing that will matter for asserting power over the economy and society will be physical control of data centers, just as physical control of capital cities has been key since at least the French Revolution” (emphasis mine).
These strike me as remarkably strong claims to make on the basis of a single feature release, and I would be hesitant to make them. Just as it would have been unwise to make sweeping pronouncements about the likely political-economic equilibrium implied by earlier models, I think the same holds.
A piece of bipartisan legislation, the “Preserving American Dominance in AI Act”, was introduced in the Senate.
Introduced by Senators Angus King (I-ME), Mitt Romney (R-UT), Jack Reed (D-RI), Jerry Moran (R-KS), and Maggie Hassan (D-NH), the legislation looks to “[establish] federal oversight of frontier AI to guard against chemical, biological, radiological, nuclear, and cyber threats.” In particular, the bill would establish the Artificial Intelligence Safety Review Office within the Department of Commerce, which would then be directed to collaborate with frontier AI model developers, and develop a take-home test for developers to evaluate their own models prior to deployment. The efficacy of this measure will, obviously, depend on the nature of the test and its administration, but the sound of a ‘take-home’ test for model developers, and their all incumbent incentives, hardly inspires confidence.
Among other things, the bill would also mandate certain reporting, know-your-customer, and cybersecurity requirements, each with the intention of reducing developers' susceptibility to breach by foreign adversaries. Overall, the bill appears relatively toothless, and about as likely to pass as most bills that pass through congress (read: not very likely). Nonetheless, it’s yet another step of national security concern over AI steadily ramping up—even if only rhetorically. Particularly, the bill’s authors make explicit reference to the need to “prioritize the national security implications of AI while ensuring the U.S. domestic AI industry remains dominant over our foreign adversaries.” Full text can be found here, and a one-page summary can be found here.
The Bipartisan AI Task Force released a landmark report.
In 273 pages and 89 recommendations covering 15 policy areas – including national security, intellectual property, the workforce, and more – the Task Force set out their vision of the principles and recommendations necessary to “advance America’s leadership in AI innovation responsibly.” The report contains some notable recommendations, as highlighted by the Center for AI Policy (CAIP), including a call for international cooperation on military use of AI, standardization of model evaluations, continual monitoring and evaluation of AI’s impact on different industries, and more. CAIP commended the report as “a critical step forward in Congressional oversight of [AI].”
Anton Leicht thinks that the political economy of AI evals is in trouble.
Evaluations of model capabilities are a staple of AI policy. Whenever policymakers and regulators want to place obligations and limitations on model developers, they will look to evals to determine whether, in a given case, those obligations and limitations apply. However, Leicht points to four characteristics of evals that undermine their efficacy.
First, many eval organizations share an uncomfortably close relationship with the world of policy. To take one example, Dan Hendrycks of the Center for AI Safety is believed to have played a significant role in shaping California’s SB1047, the landmark AI regulation vetoed by Governor Gavin Newsom earlier this year. Hendrycks also co-founded a for-profit AI safety compliance company, Gray Swan, which may have benefitted from the requirements laid out in the bill. Incestuous arrangements such as this are chum in the water for opponents of AI regulation, and undermine the viability of evals as a policy instrument. Second, media and corporate incentives mean that evals are more likely to be published if they suggest dramatic capabilities, producing a sensationalist tendency. Third, the same results can produce wildly divergent interpretations–a ‘rabbit-duck’ problem–whereby two groups can view the exact same result as straightforwardly good or straightforwardly bad, depending on their perspective. Finally, the above dramatic capability reveals are made without associated binding structure or policy response. This, Leicht argues, normalizes inaction, creating an environment in which ‘serious capability evaluation met with policy non-response’ is a dynamic to be expected.
Bonus Bits
Evan Conrad of the San Francisco Compute Company gives his thoughts on what the new test-time compute dynamic, established by OpenAI’s o-series, means for the open- versus closed-source debate.
Senior Director of AI Policy at Google DeepMind, Nicklas Lundblad, shares 8 things that surprised him in AI policy this past year.
Chairman of the US Select Committee on the CCP, Rep. John Moolenaar (R-MI) reflects on the committee’s achievements over the past year. If you didn’t know that the CCP had been operating ‘police stations’ within New York City–used to identify and harass Chinese dissidents–now you do.
The Supreme Court has fast-tracked its consideration of the TikTok ban for January.
Dylan Patel (SemiAnalysis) and Greg Allen (CSIS) join ChinaTalk to discuss their vision of a Trump administration approach to export controls.
Taiwan is in discussions with Amazon over the use of Kuiper, the tech giant's satellite internet system, should communications come under threat in the event of a Chinese invasion.
A new paper from Enrique Ide and Eduard Talamàs discusses the effect of autonomous AI on firms and workers in the knowledge economy.
Sam Altman joins Bari Weiss and the Free Press, where he discusses his feud with Elon Musk.
Tristan Williams of the Center for AI Policy outlines his vision of a better fair use policy for the AI age.
The Special Competitive Studies Project published a memo on American energy production in the context of a race to develop transformative AI.